




Ⅰ. 서 론
복행(go-around) 절차는 항공 안전에서 중요한 역할을 하며, 조종사가 안전하지 않은 착륙을 중단하고 새로운 접근을 시도할 수 있도록 한다(Figuet et al., 2023).
복행 절차는 이착륙 과정에서 발생할 수 있는 여러 위험 요소를 회피하는 중요한 방법으로, 특히 예기치 않은 환경 변화나 조종사 실수로 인한 사고를 방지하는 데 필수적이다(Kumar et al., 2021).
복행은 기본적으로 두 가지 주요 목표를 가진다: 첫째, 불안정한 접근으로 인한 사고를 방지하는 것, 둘째, 안전한 재접근을 통해 항공기와 탑승자의 안전을 보장하는 것이다(Kim et al., 2005).
김현덕(2020)은 불안정한 접근이 항공기 사고의 주요 원인 중 하나로, 복행 절차의 필요성을 높이는 주요 요인임을 강조하였다. 불안정 접근을 효과적으로 관리하기 위해서는 복행 시 항공기의 동적 반응과 조종사의 의사결정을 체계적으로 분석하는 것이 중요하다고 하였다(Kim, 2020). 동시에 데이터를 기반으로 한 안전 품질보증(quality assurance)을 통해 안전문화를 정착시켜야 한다고 말하였다(Kim, 2024).
이러한 배경에서 복행 후 항공기의 안정성을 평가하는 연구는 조종사의 의사결정 과정과 항공기 성능의 연속성을 이해하는 데 매우 중요한 역할을 한다(Monstein et al., 2022; Dhief et al., 2022).
복행의 중요성은 실제 항공 사고 사례에서도 명확히 드러난다. 2016년 두바이 국제공항에서 에미레이트 항공 521편은 착륙 시 복행을 시도했으나 기체가 지면에 충돌하여 대형 화재가 발생한 사고가 있었다. 이 사고는 복행이 제대로 수행되지 않았을 때 발생할 수 있는 위험성을 잘 보여주는 사례이다(Wingtalkers, 2023).
반면 2020년 히드로 공항에서는 강한 바람과 갑작스러운 기상 변화로 인해 착륙이 어려워진 상황에서 브리티시 에어웨이즈의 한 항공기가 복행을 결정하였다. 이 항공기는 착륙 접근 중 측풍(wind shear)을 만났고, 즉각적인 복행 결정을 통해 안전하게 상승 후 두 번째 접근을 시도하여 기상 조건이 개선된 후 안전하게 착륙할 수 있었다(Kumar et al., 2021).
이러한 사례들은 복행 절차의 중요성과 복행이 운항 중 안전성 확보에 얼마나 기여할 수 있는지를 잘 보여준다. 그러나 복행 자체가 복잡한 절차로 특히 지면에 가까운 상황에서 복행을 수행할 경우 항공기와 조종사에게 큰 부담을 주며 이로 인해 조종사의 실수나 기체의 불안정성이 발생할 수 있다(Holder, 2023).
따라서 본 연구는 운항 데이터를 활용하여 복행 후 항공기의 동적 반응과 안정성을 체계적으로 평가하는 머신러닝 모델을 개발하는 것을 목표로 한다. 이를 위해 먼저 복행을 '지면 근접 복행'과 '고도 있는 복행'으로 분류한 후 XGBoost 알고리즘을 활용해 각 유형에 따른 조종사와 항공기의 반응을 분석한다. 이 과정에서 PITCH 변화량, 강하율, 엔진 성능 및 환경적 영향을 평가하여 복행의 안정성과 효율성을 분석한다. 최종적으로 분석 결과를 바탕으로 다양한 상황을 예측하고 평가하여 복행의 안전성을 높이며 절차 개선을 위한 인사이트를 제공하고자 한다.
Ⅱ. 본 론
본 연구는 기존의 복행 이벤트 감지, 분석, 예측과 관련된 연구들을 검토하고, 현재 연구에서 적용할 방법론과 차별성을 명확히 한다. 예를 들어, Figuet et al.(2023)의 연구에서는 복행 이벤트의 발생 빈도와 영향을 분석하였고 Kumar et al.(2021)은 ADS-B 데이터를 활용한 복행 이벤트 분석을 통해 조종사의 의사결정과 기상 조건이 복행에 미치는 영향을 연구하였다. 이러한 연구들은 복행 이벤트의 중요성을 강조하였으나 복행 후의 항공기 안정성에 대한 체계적인 분석이 부족한 점이 있다. 따라서 본 연구는 이러한 부분을 보완하여 기존의 복행 연구들이 주로 복행 발생 시점이나 원인 분석에 중점을 두었던 것과 달리 복행 이후 항공기의 안정성에 대한 포괄적인 평가를 수행함으로써 연구의 차별성을 갖춘다.
XGBoost 알고리즘을 활용해 복행 이벤트의 주요 패턴과 영향을 분석하고, 이를 통해 복행 절차의 안정성 향상을 위한 인사이트를 제공하고자 한다.
XGBoost은 트리 기반 앙상블 학습 알고리즘의 하나로, 성능과 효율성을 극대화한 Gradient Boosting 알고리즘의 확장 버전이다.
이 알고리즘은 특히 대규모 데이터셋과 고차원 데이터에서 뛰어난 예측 성능을 보이며 분류와 회귀 문제를 포함한 다양한 머신러닝 과제에 널리 사용된다(Chen & Guestrin, 2016).
Gradient Boosting은 여러 개의 약한 예측 모델, 의사결정 트리를 결합하여 강력한 예측 모델을 만드는 기법이다. 이 과정은 각 단계에서 이전 모델의 오류를 최소화하는 방향으로 새로운 모델을 추가함으로써 수행된다. 각 모델은 이전 모델이 예측하지 못한 부분을 보완하는 방식으로 학습된다(Friedman, 2001).
Gradient Boosting은 모델이 학습하는 과정에서 손실 함수 를 최소화하기 위해 이전 모델의 오류를 보완하는 새로운 모델을 추가하며 수식 1과 같다(Friedman, 2001).
여기서 Fm (x)는 현재모델, Fm-1 (x)는 이전모델, γm는 학습률, hm (x)는 새로운 약한 모델이다.
XGBoost는 이 기본 개념을 바탕으로 여러 가지 고급 기능을 추가하여 성능을 극대화한다. 주요 확장 기능으로 정규화 항을 도입하여 과적합을 방지하는 것이며 수식 2와 같이 정리된다.
여기서T는 트리의 노드수, wj는 리프노드의 가중치, γ와 λ는 정규화 매개변수이다(Chen & Guestrin, 2016).
이 수식은 XGBoost의 모델이 복잡해지는 것을 방지하고 데이터의 일반화 능력을 향상시키는 역할을 한다. 이러한 특성 덕분에 XGBoost는 대규모 데이터셋과 복잡한 문제에서 높은 성능을 보장할 수 있다.
본 연구는 운항 데이터를 활용하여 복행 이벤트를 감지하고 복행 후 항공기의 안정성을 분석하는 것이다. 이를 위해 머신러닝 기법을 적용하여 복행 시나리오를 모델링하고 각 상황에서 항공기의 동적 반응을 평가한다. 연구의 주요 단계는 데이터 수집 및 전처리, 피처 엔지니어링, 모델 개발 및 훈련, 그리고 모델 평가로 구성된다.
연구에 사용되는 데이터는 QAR 시스템을 통해 2021년부터 24년까지 수집된 3개년의 항공기 운항 데이터이며 사용된 파라미터의 정의는 Table 1과 같다.
각 데이터 포인트는 특정 복행 이벤트 전후의 시간을 포함하며 복행의 시작 시점과 종료 시점을 명확하게 정의한다. 수집된 데이터는 전처리 과정을 거쳐 분석에 적합한 형태로 변환된다. 전처리 과정에는 결측값 처리, 이상치 제거, 데이터 정규화 등이 포함된다. 또한 복행 이벤트는 지면 근접 복행과 고도 있는 복행으로 분류되며 각 유형에 따라 별도의 분석이 이루어진다.
복행 이벤트의 분석을 위해 추출한 파라미터들은 복행의 안정성과 효율성을 평가하는 목적으로 사용된다. 예를 들어, Pitch Attitude와 Pitch Attitude Rate는 항공기의 기수 조절 능력을 평가하는 데 중요한 역할을 하며 Vertical Speed와 Wind Direction은 외부 환경이 항공기에 미치는 영향을 분석하는 데 사용된다. 이러한 파라미터들을 적절히 선택하고 가공하는 과정은 모델의 성능을 결정짓는 핵심 단계로 피처 엔지니어링(feature engineering)이라 한다.
피처 엔지니어링은 데이터에서 의미 있는 특성을 추출하고 변형하는 과정으로 모델이 주어진 문제를 보다 정확하게 예측할 수 있도록 한다. 본 연구에서는 피처 엔지니어링을 통해 XGBoost 알고리즘을 사용하여 각 특성의 중요도를 평가함으로써 복행 이벤트에서 가장 중요한 역할을 하는 파라미터를 식별할 수 있다.
이를 통해 복행 이벤트에서 가장 중요한 역할을 하는 파라미터를 식별하고 모델의 성능을 향상시키기 위한 특성 선택을 최적화한다.
본 연구에서는 XGBoost 알고리즘을 사용하여 복행 후 항공기의 동적 반응을 모델링한다. 모델 훈련은 수집된 데이터를 훈련 세트와 테스트 세트로 나누어 진행하며 교차 검증(cross-validation)을 통해 모델의 일반화 성능을 평가하고 최적의 모델을 도출하기 위해 하이퍼파라미터 튜닝(hyperparameter tuning)이 이루어진다. 이 과정에서는 그리드 검색(grid search) 또는 랜덤 검색(random search)을 사용하여 학습률, 트리의 최대 깊이, 정규화 매개변수 등의 하이퍼파라미터 조합을 최적화하여 모델의 예측 정확도를 극대화하고 과적합을 방지한다.
모델 개발의 주요 목표 중 하나는 복행 과정에서 항공기의 기수 조작(pitch attitude)과 이에 따른 변화 속도(pitch attitude rate)를 분석하여 복행이 안정적으로 이루어졌는지 평가하는 것이다. 특히, 복행 중 기수의 급격한 변화가 항공기의 안정성과 탑승자 안전에 미치는 영향을 중점적으로 분석한다.
또한 비정상적인 복행 패턴을 식별하기 위해 Throttle Lever Angle, N1 Actual, Pitch Attitude, Vertical Speed 등의 파라미터를 포함한 모든 데이터를 활용하여 정상적인 복행과 비교했을 때 과도한 속도 변화, 엔진 출력의 불균형 또는 기수 조작의 이상 패턴을 탐지함으로써 복행 중 발생할 수 있는 잠재적 위험 요소를 사전에 파악한다.
아울러 복행 유형에 따라 '지면 근접 복행'과 '고도 있는 복행'으로 분류하여 각각의 성능을 분석한다. 지면 근접 복행에서는 높은 Pitch Attitude와 Pitch Attitude Rate를 중점적으로 분석하며 지면과 가까운 상태에서의 복행은 Tail Strike의 위험이 존재하므로 급격한 기수 조작이 항공기의 안전에 미치는 영향을 평가한다. 반면 고도 있는 복행에서는 에너지 관리에 중점을 두어 플랩 전개 및 랜딩기어를 접는 속도가 리미트 스피드에 근접한 상태에서의 비행을 평가하고 낮거나 느린 Pitch Attitude와 Pitch Attitude Rate 조절이 복행 중 항공기의 효율성과 안정성에 어떻게 기여하는지를 분석한다.
모델의 성능은 테스트 데이터를 사용하여 평가된다. 평가 메트릭으로는 회귀 모델에 적합한 지표들이 사용하며 사용된 지표들은 다음과 같다.
Mean Squared Error (MSE)은 예측 값과 실제 값 사이의 평균 제곱 오차를 나타낸다. 값이 낮을수록 모델의 예측이 실제 값에 가까움을 의미한다. Root Mean Squared Error (RMSE)는 MSE의 제곱근으로 예측 오류의 평균적인 크기를 나타낸다. RMSE 역시 값이 낮을수록 예측의 정확도가 높다는 것을 의미한다.
Mean Absolute Error (MAE)는 예측 값과 실제 값 간의 절대적 차이의 평균을 나타내며 MAE 값이 작을수록 모델의 예측이 더 정확하다.
R² Score 값은 모델이 데이터의 변동성을 얼마나 잘 설명하는지를 나타내는 지표로 1에 가까울수록 모델이 데이터를 잘 설명하고 있음을 의미한다.
총 368개의 복행 데이터를 CSV 파일에서 통합하였고 각 파일의 데이터를 하나의 데이터프레임으로 병합하였다. TOGA(Take Off & Go Around) 시점 탐지 및 데이터 분할을 위해 Throttle Lever Angle이 30 이상인 시점을 TOGA 시점으로 설정하고, TOGA 전후 10초 동안의 데이터를 분석에 사용하였다.
수집된 데이터는 변수마다 센싱 주기가 달랐기 때문에 이를 동일한 시간 축으로 맞추기 위해 데이터 동기화 작업을 수행하였다.
Pitch Attitude 변수의 1초에 4번(0.25초 간격) 측정되는 주기를 기준으로 하였다.
Normal Acceleration과 LDG Squat Switches 변수는 1초에 8번 측정되므로 1초에 4번의 주기로 다운 샘플링 하였고 Vertical Speed와 같이 1초에 1회 측정되는 변수들은 선형 보간법1)을 통해 결측값을 채웠다. 단순 Con uration을 나타내는 Flap Position은 전진 보간(Forward Fill)을 사용하여 이전 시간의 값으로 결측값을 채워 데이터의 연속성을 확보하였다.
전처리된 데이터를 바탕으로 분석의 목표를 달성하기 위해 비정상적 복행 패턴을 탐지하기 위해 주요 변수를 신중히 선택하고 파생 변수를 생성하였다.
선택한 변수는 Table 1과 같으며 복행 절차의 분석을 다각도에서 수행하기 위해 Table 2와 같은 파생 변수를 생성하였다.
생성된 변수들 중 각 변화속도를 측정하는 Rate는 차분 값으로 계산하였고 Thrust Difference는 ENG1과 ENG2의 차이로 Energy Parameter는 항공기의 속도와 고도를 결합하여 계산하였다.
스케일링은 XGBoost와 같은 트리 기반 모델은 변수 스케일링에 민감하지 않기 때문에 수행하지 않았다.
본 연구에서는 XGBoost 모델을 활용하여 Pitch Attitude, Vertical Speed, Normal Acceleration 등 주요 변수의 Z-score를 기반으로 복행 절차의 안정성을 평가하였다. Z-score는 각 변수의 값이 평균으로부터 얼마나 벗어나 있는지를 측정하는 지표로, 비정상적인 변화를 감지하는 데 사용되었다.
모델링 과정에서, 먼저 각 변수에 대해 Z-score를 계산하였다. 이때 Z-score가 특정 임계값(예: 3.5, 3.8, 4.0)을 초과하는 경우 이를 비정상적인 상황으로 정의하였다. 이와 같은 비정상적인 상황은 XGBoost 모델의 피처로 포함되어 복행 절차 중 발생할 수 있는 위험성을 예측하는 데 사용되었다.
또한, RA 15ft를 기준으로 복행 절차를 지면 근접 복행과 고도 있는 복행으로 분류한 후 각 유형별로 비정상적인 패턴을 분석하였다. 이를 통해 XGBoost 모델이 복행 절차의 안정성을 보다 정밀하게 평가할 수 있도록 하였다.
TOGA 이후 안전한 복행 여부를 예측하기 위해 XGBoost 모델을 사용하여 모델링하였다. XGBoost는 부스팅 트리(boosted trees) 알고리즘을 기반으로 하여 각 단계에서 예측 오류를 최소화하도록 모델을 순차적으로 개선해 나가는 방식으로 동작한다. 본 연구에서 사용된 모델의 주요 구성은 하이퍼파라미터의 설정이었다. XGBoost 모델의 성능을 최적화하기 먼저 개별 결정 트리의 최대 깊이를 설정하는 Max_Depth는 6으로 설정되었다. 이 값은 모델이 학습할 수 있는 피처 간의 복잡한 관계를 충분히 반영할 수 있도록 한다. Learning_Rate는 0.1로 설정되었으며 이는 각 부스팅 단계에서 가중치 조정의 크기를 세밀하게 조절하여 모델의 일반화 성능을 높이는 데 기여하였다.
모델이 학습 과정에서 생성할 트리의 수를 결정하는 N_Estimators는 100으로 설정되었다. 많은 트리를 사용할수록 모델의 예측 능력이 향상될 수 있지만 과적합의 위험도 증가할 수 있음을 고려하였다. 또한 Subsample 파라미터는 0.8로 설정되었으며 각 트리 학습에 사용할 데이터의 80%를 무작위로 선택하여 학습함으로써 과적합을 방지하였다. 마지막으로 모델의 성능을 평가하는 지표로 Eval_Metric은 Logloss2)로 설정되어 이진 분류 문제에서의 성능 최적화에 중점을 두었다.
모델 학습 과정은 전체 데이터를 훈련 데이터와 검증 데이터로 분할한 후 진행되었다. 전체 365편의 비행 데이터를 80%인 292편의 훈련 데이터와 20%인 73편의 검증 데이터로 나누었다. 이 중 13편은 안전하지 않은 복행으로 분류되었다.
전처리 데이터를 바탕으로 타겟 변수 설정을 수행하였고 복행 절차 중 안전하지 않은 상황을 정의하고 이를 바탕으로 이진 분류 타겟 변수를 생성하였다. 주요 지표로는 항공기의 Pitch Attitude, Rotation Rate, Roll Angle 등이 사용되었다.
모델 훈련은 준비된 훈련 데이터를 사용하여 진행되었다. 이 과정에서 XGBoost 모델은 각 부스팅 단계에서 발생하는 오차를 최소화하면서 피처 간의 복잡한 상관관계를 학습하였다.
또한 초기 모델 성능 분석 결과를 바탕으로 하이퍼파라미터 튜닝이 진행되었다. Grid Search와 Random Search 기법을 사용하여 최적의 하이퍼파라미터 조합을 탐색하였으며 이를 통해 모델의 성능을 최대한으로 향상시켰다.
모델 학습 후 모델 평가는 테스트 데이터를 사용하여 수행되었다. 평가 과정에서는 혼동 행렬, Precision, Recall, F1-score 등의 성능 지표를 사용하여 모델의 예측 능력을 종합적으로 분석하였다. 특히 안전하지 않은 복행을 정확히 예측하는 데 중점을 두고 평가가 이루어졌다.
Fig. 1은 모델의 정확도 결과이며 94.7%의 검증용 데이터(73편) 중 약 94.7%의 사례에서 모델이 올바르게 예측했음을 의미한다. 이 결과는 모델이 대부분의 복행 사례를 정확히 예측할 수 있음을 나타낸다.
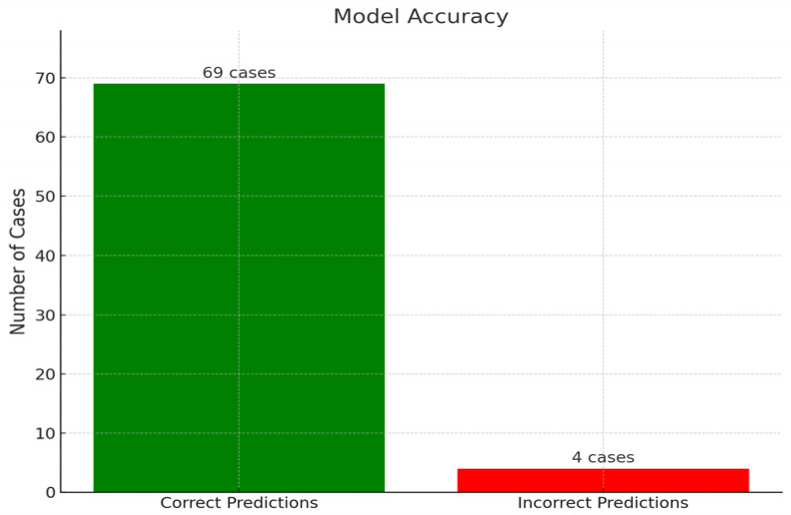
Fig. 2는 혼동 행렬(confusion matrix)의 결과로 모델은 55편의 비행에서 안전한 복행 여부를 정확히 예측하였다. 이는 모델이 이 55편의 비행을 안전한 복행으로 분류하였으며 실제로도 이 비행들은 안전한 복행이었음을 의미하며 True Positives (1, 1)로 정의된다.

True Negatives (0, 0)으로 정의되며 12편의 비행에서 모델은 안전하지 않은 복행을 올바르게 예측하였다. 즉 이 12편의 비행은 실제로도 안전하지 않은 복행이었으며, 모델이 이를 정확히 안전하지 않은 복행으로 분류하였다.
False Positives에서는 (0, 1) 값을 가지며 1편의 비행에서 모델은 오류를 범하였다. 이 비행은 실제로는 안전하지 않은 복행이었음에도 불구하고, 모델은 이를 안전한 복행으로 잘못 예측하였다.
False Negatives에서는 (1, 0) 값을 가지고 5편의 비행에서도 모델이 실수를 하였다. 이 비행들은 실제로는 안전한 복행이었으나 모델은 이를 안전하지 않은 복행으로 잘못 예측하였다.
모델의 성능을 보다 구체적으로 평가하기 위해 Precision, Recall, F1-score를 분석하였다.
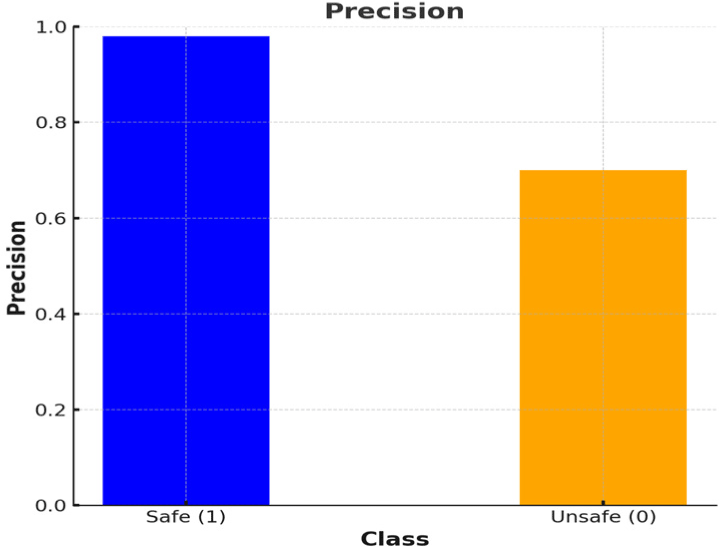
Precision은 모델이 특정 클래스(안전한 복행 또는 불안전한 복행)로 예측한 사례들 중 실제로도 그 클래스에 해당하는 사례의 비율을 의미한다.
Fig. 3을 보면 안전한 복행(1)에 대한 Precision은 98%로 나타났다. 이는 모델이 안전한 복행으로 예측한 사례 중 98%가 실제로도 안전한 복행임을 의미한다. 반면, 불안전한 복행(0)에 대한 Precision은 70%로 이는 모델이 불안전한 복행으로 예측한 사례 중 70%가 실제로도 안전하지 않은 복행임을 의미한다.
Recall은 실제로 특정 클래스에 속하는 사례들 중에서 모델이 해당 클래스로 정확히 예측한 비율을 나타낸다.
Fig. 4는 안전한 복행(1)에 대한 Recall이 **91%**로 측정되었다.
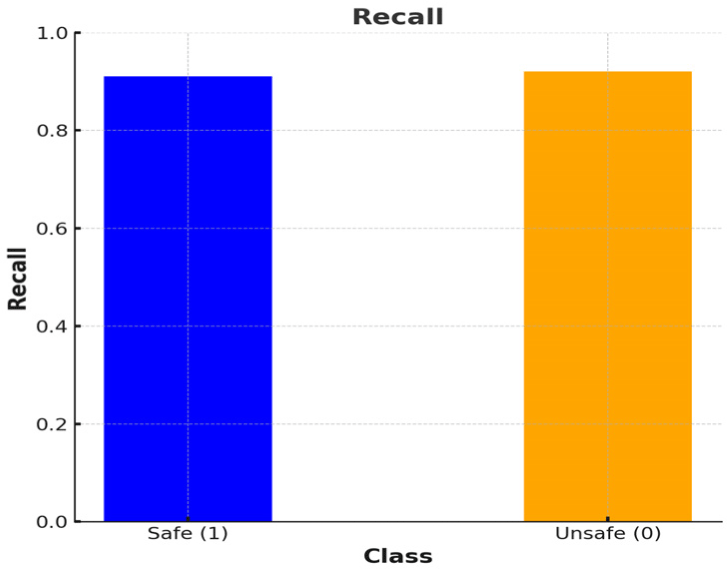
이는 실제로 안전한 복행 사례 중 91%를 모델이 정확하게 예측했음을 의미한다. 반면, 불안전한 복행(0)에 대한 Recall은 **92%**로, 실제 불안전한 복행 사례 중 92%를 모델이 정확하게 예측했음을 의미한다.
F1-score는 Precision과 Recall의 조화 평균으로 모델의 예측 성능을 종합적으로 평가하는 지표이다. 모델의 F1-score는 Fig. 5와 같다.
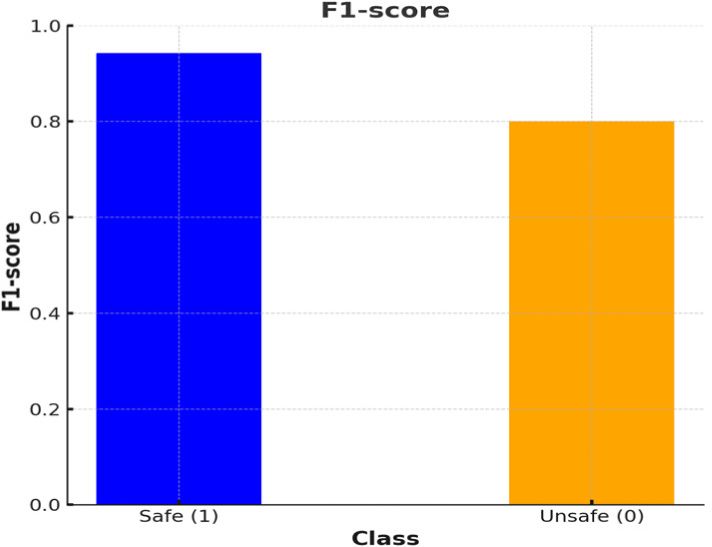
안전한 복행(1)에 대한 F1-score는 94.3%로 이는 모델이 안전한 복행을 예측하는 데 있어 높은 수준의 정확성과 재현성을 유지하고 있음을 나타낸다. 불안전한 복행(0)에 대한 F1-score는 80%로 모델이 불안전한 복행을 예측하는 데 있어서도 비교적 좋은 성능을 보이고 있음을 보여준다.
본 연구는 Airbus A321 기종의 복행(go-around) 절차를 체계적으로 분석하고, 항공기의 동적 반응과 안정성을 평가하기 위해 XGBoost 회귀분석 모델과 Z-score를 결합하여 활용하였다. 주요 변수인 Pitch Attitude, Vertical Speed, Normal Acceleration 등에 대한 Z-score를 기반으로 비정상적인 상황을 감지하고 이를 XGBoost 모델에 반영함으로써 복행 절차 중 발생할 수 있는 다양한 위험 요소를 효과적으로 예측할 수 있었다.
또한 복행 절차를 지표면으로부터의 고도인 RA(radio altimeter) 15ft를 기준으로 지면 근접 복행과 고도 있는 복행으로 분류하여 각각의 특성을 분석함으로써 항공기의 기수 각도 변화, 수직 속도, 가속도 등 다양한 변수들의 영향을 보다 구체적으로 파악할 수 있었다.
XGBoost 휘귀분석을 통해 복행 절차의 안정성을 평가하였다. 이 과정에서 비정상적인 상황과 정상적인 상황을 구분하여 각각의 경우를 세밀하게 평가하였다.
먼저 Pitch Attitude 분석 결과, 총 365편의 데이터 중 8편(약 2.2%)에서 비정상적인 변화가 나타났다. 이들 비행에서는 Z-score가 3.5 이상으로, Pitch Attitude가 약 12도 이상 급격히 상승한 사례였다.
Vertical Speed의 경우, 365편의 비행 중 10편(약 2.7%)에서 급격한 변동이 감지되었다. 정상적인 수직 속도에서 Z-score가 3.8 이상으로, 수직 속도가 평균보다 높았으며 1,500 ft/min 이상 급격하게 상승하거나 하강한 경우가 비정상적인 상황으로 정의되었다.
Normal Acceleration에서는 7편(약 1.9%)의 비행에서 비정상적인 가속도가 관찰되었다. 이들 비행에서는 Z-score가 4.0 이상으로 나타났으며, 가속도가 평균보다 1.8g 이상 급격히 변화한 사례였다.
다음으로 복행 유형별 성능 분석 결과, 모델은 RA 15ft를 기준으로 복행 절차를 지면 근접 복행과 고도 있는 복행으로 분류하였다. 지면 근접 복행에서는 총 50편 중 6편(약 12%)에서 비정상적인 패턴이 관찰되었다. 이 유형에서는 특히 Pitch Attitude와 Pitch Attitude Rate의 급격한 변화가 중요한 평가 지표로 나타났다. 비정상적인 지면 근접 복행의 경우 Pitch Attitude가 10도 이상 급변하거나 Pitch Attitude Rate가 4.5도/초를 초과하여 급격히 변화한 사례가 있었다. 이러한 경우는 Tail Strike 위험을 증가시키며, 복행 절차 중 항공기의 기수 각도 제어에 큰 문제가 발생할 수 있음을 시사한다.
한편, 고도 있는 복행에서는 총 315편 중 7편(약 2.2%)에서 비정상적인 패턴이 관찰되었다. 이 유형에서는 주로 에너지 관리와 관련된 변수들이 중요하게 평가되었다. Pitch Attitude가 너무 낮아져 항공기의 에너지가 급격히 증가 또는 감소하거나, 기체가 Limit Speed에 근접한 사례들이 있었다. 특히, 비정상적인 고도 있는 복행의 경우 Pitch Attitude가 5도 이하로 떨어지면서 Limit Speed에 근접하는 상황이 나타났다.
이러한 분석 결과를 통해 복행 절차 중 발생할 수 있는 위험 요소를 사전에 인지하고 이를 예방할 수 있는 절차와 추가적인 훈련 프로그램의 필요성을 강조할 수 있다.
Ⅲ. 결 론
본 연구에서는 XGBoost 모델을 활용하여 Airbus A321 기종의 복행(Go-Around) 절차 중 항공기의 동적 반응과 안정성을 평가하려는 시도를 하였다. 연구의 핵심은 복행 절차에서 발생할 수 있는 비정상적인 상황을 감지하고 이를 바탕으로 복행 절차의 안정성을 평가하고 분류하는 데 중점을 두었다.
특히, XGBoost 회귀분석결과를 바탕으로 분류 알고리즘을 모델링하여 사용하여 복행 절차에서 안전한 상황과 비정상적인 상황을 구분하였다. 이 모델은 Pitch Attitude, Vertical Speed, Normal Acceleration 등의 주요 변수를 분석하여 복행 절차 중 항공기의 반응을 분석 가능하며 모델은 복행 절차의 여러 단계에서 발생할 수 있는 위험 요소를 효과적으로 탐지하고 복행의 안정성을 체계적으로 평가할 수 있었다.
이 과정에서 Z-score를 활용하여 주요 변수들의 비정상적인 변화를 탐지한 결과, 365편의 비행 데이터 중 각각 8편(약 2.2%), 10편(약 2.7%), 7편(약 1.9%)에서 비정상적인 상황이 발생한 것을 확인하였다. 이러한 결과는 복행 절차 중 일부 항공기의 동적 반응이 정상 범위를 벗어날 수 있음을 시사하며 이와 같은 상황이 복행 절차의 안전성에 영향을 미칠 수 있음을 보여준다.
또한 RA 15ft를 기준으로 복행 절차를 지면 근접 복행과 고도 있는 복행으로 분류하고 각 유형별로 성능을 분석하였다. 지면 근접 복행에서는 50편 중 6편(약 12%)에서, 고도 있는 복행에서는 315편 중 7편(약 2.2%)에서 비정상적인 패턴이 감지되었다. 이러한 분석을 통해, 복행 절차 중 발생할 수 있는 다양한 위험 요소를 식별하고 평가할 수 있었다.
비록 본 연구는 제한된 데이터와 분석 범위 내에서 수행되었지만 XGBoost 모델을 통해 복행 절차 중 항공기의 동적 반응을 평가하고 정상 복행과 비정상 복행을 탐비할 수 있는 알고리즘을 모델링하였고 항공데이터를 바탕으로 전조징후의 탐지 가능성을 도출하였다. 이 결과는 복행 절차의 안전성을 높이기 위한 기초 자료로 활용될 수 있으며 향후 연구에서는 보다 다양한 데이터와 심층 분석을 통해 이 모델의 적용 가능성을 더욱 넓혀갈 수 있을 것이다.